
Cultural Adaptation in AI Localization
How to build a futureproof relationship with AI

AI localization involves tailoring machine learning outputs to specific languages and regions by incorporating local norms, idioms, and styles. While AI models like GPT-4o hold vast cultural knowledge, they often fail to apply it naturally without explicit prompts. This gap, called the "explicit-implicit localization gap", highlights the challenge of making AI-generated content feel natural in different contexts. For example, the color of pumpkins is perceived as "orange" globally but "green" in Japan - a distinction AI models often miss without specific guidance.
Key points covered include:
Language and Style Adjustments: AI adapts differently based on language, e.g., English outputs lean toward individualism, while Chinese outputs reflect interdependence.
Challenges with Idioms and Norms: AI struggles with abstract values, minority languages, and situational etiquette, often requiring explicit prompts to align with local expectations.
Bias in Datasets: Training data skews heavily toward English and Western perspectives, sidelining many regions and languages.
Human-AI Collaboration: Native speakers and local reviewers are crucial for refining AI outputs, especially in low-resource languages.
Emerging solutions include steering techniques to fine-tune models for specific regions, localized datasets like CultureVerse for training, and tools like TwinTone for multilingual content production. However, challenges persist, particularly in balancing accuracy and avoiding stereotypes in diverse regions.
How AI Handles Cultural Adaptation Today
Language and Style Adaptation
AI models demonstrate different cognitive approaches based on the language they’re working with. For instance, research shows that GPT adopts a "holistic" style when operating in Chinese, while it leans toward an "analytic" style in English. This difference goes beyond just language - it directly impacts how AI generates commercial outputs. For example, when prompted in Chinese, models are far more likely to recommend advertisements that highlight interdependent social values compared to those prompted in English.
However, these adaptations don’t happen automatically. While large language models (LLMs) are packed with cultural knowledge, they often default to English-centric patterns unless specifically instructed otherwise. As Veniamin Veselovsky from Princeton University puts it:
"Cultural knowledge, while present in these models, may not naturally surface during multilingual interactions".
To address this, developers are exploring techniques like "cultural steering vectors." These methods help shift AI models from a Western-centric perspective to a specific cultural framework without needing repeated explicit prompts. The cost of implementing such adjustments has dropped significantly, with fine-tuning a culturally-aware model now costing as little as $6 using the OpenAI API.
These advances are promising but highlight ongoing challenges, particularly when AI encounters non-textual cultural elements.
Handling Idioms, Humor, and Etiquette
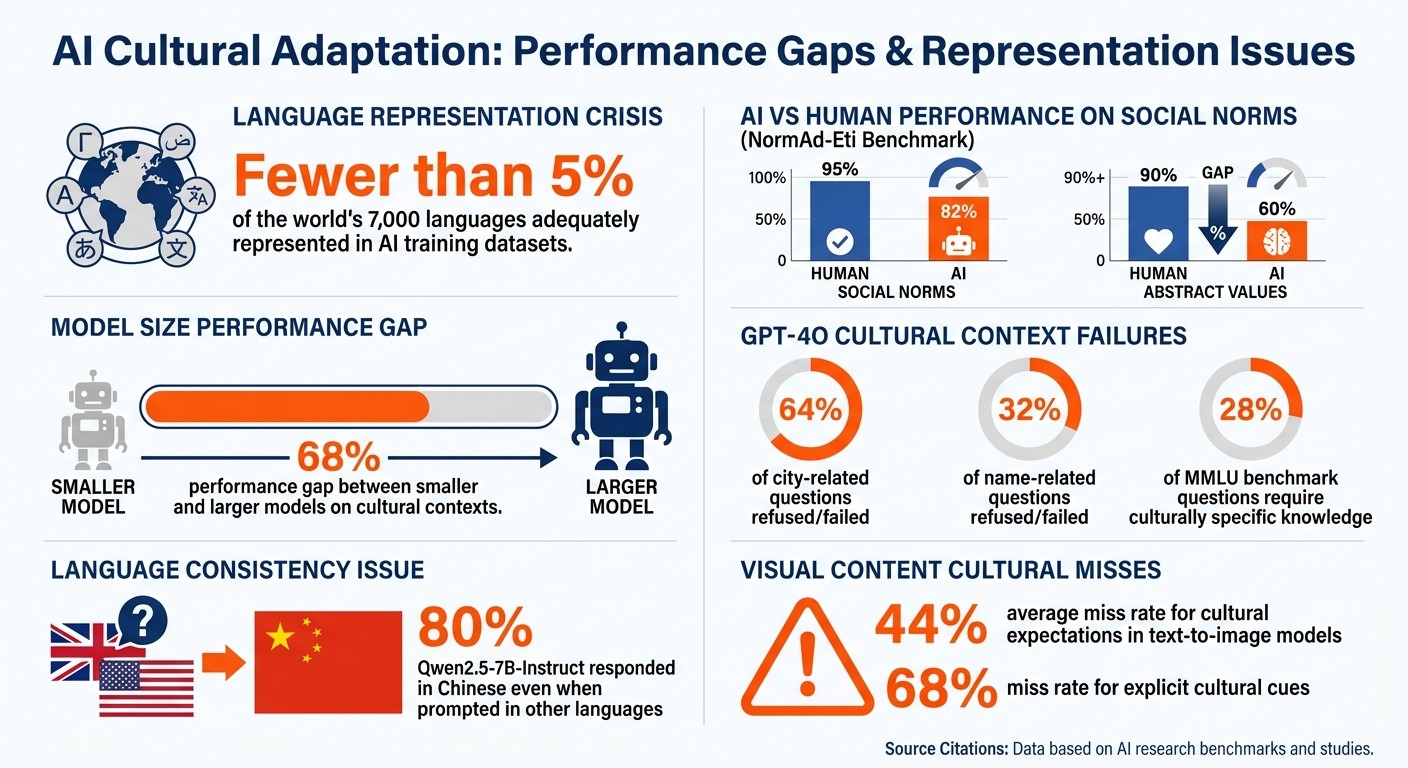
When it comes to understanding social norms, idioms, and etiquette, AI still struggles to match human accuracy. The NormAd-Eti benchmark, introduced at NAACL 2025, evaluated AI performance across 2,600 situational descriptions from 75 countries. The findings were clear: even the best-performing LLMs scored below 82% in judging social acceptability, while humans consistently achieved over 95% accuracy. The gap widened in scenarios involving abstract values or country-specific details, where AI performance dropped below 60%, compared to humans maintaining over 90% accuracy.
"LLMs struggle to accurately judge social acceptability across these varying degrees of cultural contexts and show stronger adaptability to English-centric cultures over those from the Global South." - Abhinav Rao, Researcher
The problem becomes even more pronounced with minority languages. For example, GPT-4o has been documented refusing to answer up to 64% of city-related and 32% of name-related questions when lacking cultural context. This is likely due to safeguards designed to avoid bias.
Another concern is how AI homogenizes content. A CHI 2025 study involving 118 participants from India and the U.S. revealed that AI writing assistants often nudge users toward Western norms. Researcher Dhruv Agarwal observed:
"Western-centric AI models homogenize writing toward Western norms, diminishing nuances that differentiate cultural expression".
Indian participants who relied on AI suggestions found their writing styles shifting toward Western conventions, which diluted their cultural identity.
Next, we’ll explore how AI tackles cultural nuances in visual and auditory content.
Video and Audio Localization
Expanding beyond text, AI is now working to adapt visual and auditory content to fit cultural contexts. Modern Vision-Language Models are designed to handle these elements, moving from basic translation to full multimodal localization. The CultureVerse benchmark, which includes 19,682 cultural concepts from 188 countries across 15 categories, plays a key role in training these models to recognize cultural symbols, gestures, and artifacts.
New tools like CLCA use simulated interactions to capture implicit cultural norms. Similarly, Microsoft’s Adaptive Custom Translation (adaptCT) system can adjust to specific domain terminology and cultural styles with as few as 5 to 10,000 reference sentence pairs. Impressively, these updates can take effect in minutes, compared to the 48-hour turnaround required by traditional methods.
Despite these advances, balancing accuracy with authenticity remains a challenge. While culturally explicit prompts can improve localization, they also risk increasing content homogenization by over 3% and may inadvertently reinforce stereotypes.
How to Stop AI From Flattening Culture and Meaning
Challenges and Limitations in AI Cultural Adaptation
AI Cultural Adaptation Performance Gaps and Key Statistics
Bias and Representation Problems
AI systems often grapple with significant challenges in accurately representing the world's diverse cultures and languages. A key issue lies in the datasets these models are trained on, such as Common Crawl, which heavily skew toward English and Western perspectives. This imbalance is stark: fewer than 5% of the world's 7,000 languages are adequately represented in these datasets. On top of that, safety filters frequently exclude non-English content due to limited processing capabilities, further sidelining underrepresented cultures.
The practical implications of this bias are evident. For instance, GPT-4o, when not provided with explicit cultural context, failed to answer 64% of city-related and 32% of name-related questions accurately. Moreover, about 28% of questions in the MMLU benchmark - a test often regarded as "neutral" - require culturally specific knowledge to answer correctly. This creates what some call a "cultural prompt engineering tax", where users from non-Western backgrounds must provide more detailed instructions to achieve the same level of accuracy as their Western counterparts.
Genevieve Smith from Berkeley's BAIR Lab sheds light on the deeper implications of these biases:
"Language carries power. Reinforcing a particular way of speaking reflects what linguists call 'standard language ideology' - the belief that one variety is correct. It's ultimately a power balance issue."
These systemic biases pave the way for further cultural missteps, as explored below.
Cultural Errors and Misinterpretation
When AI lacks high-quality regional data, it often produces authoritative but incorrect responses, a problem exacerbated by its inability to recognize its own limitations. A striking example comes from early 2023, when Álvaro Soto, Director of Chile's National Center for Artificial Intelligence (CENIA), asked ChatGPT about a 1942 short story by Jorge Luis Borges titled Las doce figuras del mundo. Instead of admitting it lacked the information, ChatGPT fabricated a plausible-sounding but entirely incorrect title. Soto reflected on this issue:
"These models were not trained with quality data from our region. When they don't find specific information, they make it up."
This issue is further highlighted by what’s called the "explicit-implicit localization gap." In one instance from April 2025, when asked in Japanese about the color of pumpkins, GPT-4o initially answered "orange", reflecting an American norm. It wasn’t until the prompt explicitly referred to Japanese context that the model correctly identified the color as "green".
These errors go beyond simple misunderstandings. They point to a deeper problem: AI’s tendency to present inaccuracies with undue confidence.
Overconfidence and Lack of Transparency
One of the most troubling flaws in AI cultural adaptation is its overconfidence. AI models often deliver responses with an authoritative tone, even when the information is inaccurate or culturally insensitive. Leslie Teo, Director of AI Products at AI Singapore, highlights the risks of this issue:
"If people don't feel the AI understands them, or if they can't access it, they won't benefit from it."
This overconfidence can also erode cultural authenticity. A cross-cultural study involving 118 participants from India and the United States found that AI writing suggestions led Indian participants to adopt Western writing styles, diluting their unique cultural expression. Instead of fostering cultural understanding, overconfidence masks inaccuracies and perpetuates stereotypes.
Adding to the challenge is the lack of transparency in training data, which makes it harder to verify the accuracy of AI outputs. While explicit cultural prompts can sometimes improve alignment, they also risk producing stereotypical responses. Smaller models, in particular, struggle with cultural nuances, showing up to a 68% performance gap compared to larger models when handling culturally specific contexts.
Strategies for Better AI Localization
Data-Driven Localization Methods
Improving how AI systems adapt to different cultural contexts starts with refining how they process cultural information. A study from Princeton University in April 2025 highlighted a simple yet effective method: adding culturally specific terms - like local dishes, currencies, or cities - to prompts. For example, including words like “Tokyo” or “yen” can instantly shift the AI's cultural perspective, often eliminating the need for lengthy contextual explanations.
More advanced techniques, such as activation steering, take this a step further. Developers can target specific layers in AI models (e.g., layers 19–28 in models like Gemma-2) and apply linear steering vectors to fine-tune responses for cultural relevance without requiring explicit prompts. This method strikes a balance between maintaining diverse outputs and achieving precise localization.
Another key factor is training on comprehensive datasets. Models fine-tuned on resources like CultureVerse - which encompasses over 19,000 cultural concepts spanning 188 countries - demonstrate better multicultural understanding without losing their overall performance. Additionally, creating regional sub-variants of languages, such as tailored versions of Spanish for Latin America and Spain, helps address sociolinguistic differences and fosters greater user trust.
While these data-driven approaches have led to significant progress, smaller models still struggle with culturally specific contexts. Larger models, however, show noticeable improvements when provided with explicit cultural cues. These advancements lay the groundwork for integrating human expertise, as explored in the next section.
Human-AI Collaboration
Even the best data-driven methods can’t replace the nuanced understanding that humans bring to the table. Native speakers play a critical role in reviewing prompts to ensure they are fluent, grammatically accurate, and culturally appropriate - especially in languages with complex grammar structures. This human oversight is essential for leveraging AI’s cultural capabilities effectively, as models often default to English-centric responses unless explicitly guided.
The most impactful strategy involves collaborating with local communities to ensure AI systems respect and reflect authentic cultural priorities rather than imposing Western-centric perspectives. For example, human reviewers can evaluate subtleties like proper honorific usage in Korean, which goes beyond mere factual correctness.
A practical example of this need for human involvement comes from the MakiEval framework, which tested seven large language models across 13 languages in September 2025. It found that models like Qwen2.5-7B-Instruct responded in Chinese 80% of the time, even when prompted in other languages. Human intervention was required to enforce language consistency and ensure culturally accurate responses. This underscores why human oversight remains a cornerstone of effective localization. To gauge the success of these efforts, robust evaluation metrics are indispensable.
Quality Metrics and Evaluation
Traditional metrics focused on accuracy alone aren’t sufficient for measuring cultural adaptation. Modern evaluation frameworks emphasize cultural assessment that goes beyond treating culture as trivia, instead analyzing how cultural nuances influence AI interactions. These metrics create a feedback loop, helping refine both data-driven and human-centric strategies.
The Hierarchical Adaptability Framework (NormAd) is one such tool. It evaluates a model’s ability to navigate cultural contexts across three levels: specific social rules, country-level context, and broader societal values. This helps identify areas where AI systems need to improve their understanding of cultural subtleties.
Other multi-dimensional metrics dive deeper than simple right-or-wrong answers. They assess factors like the omission of key cultural symbols, the coherence of cultural references, and the appropriate use of politeness markers. For instance, in text-to-image models, cultural expectations are missed 44% of the time on average, with explicit cultural cues being overlooked 68% of the time.
Developers should also pay attention to the explicit-implicit localization gap - the difference in performance when cultural context is explicitly provided versus naturally inferred through language. Monitoring this gap helps pinpoint areas where cultural knowledge exists within the model but doesn’t surface effectively during multilingual interactions.
Impact on AI-Powered Creator Platforms
Localized Creator Personas
AI-powered creator platforms are stepping up their game by tailoring creator personas to connect with regional audiences. The challenge? Keeping the creator's voice authentic while adapting to diverse cultural preferences. This involves fine-tuning tone and style to align with local expectations. Research shows that AI models naturally adapt their cultural tendencies based on the language they're working in. For instance, content in Chinese often reflects a more interdependent tone, while English outputs lean toward individualism.
Why does this matter? Because language resonates. A whopping 82% of shoppers are more likely to buy a product when ads are in their native language. A great example of this is Gaijin Entertainment's 2025 campaign for War Thunder in Korea. Instead of just translating English ads, they incorporated local landscapes and historical references. The result? Double the conversion rates at half the cost per acquisition.
Thanks to recent advancements in model tuning, cultural alignment is becoming smarter and easier. Simple tweaks, like adding localized cues to prompts, can shift an AI's cultural lens, making content feel more authentic to specific audiences.
24/7 Multilingual Content Automation
Traditional content localization can be a headache, especially when timelines stretch endlessly. For example, dubbing a 12-hour video series can take 3.5 months and require over 50 voice actors. AI automation is flipping the script, slashing production time while maintaining quality across multiple languages.
Take the case of Amobear, a Vietnamese developer that used AI-powered video dubbing to enter European markets in 2025. By creating German- and Spanish-dubbed ads for their face-swapping app, they saw impressive results: a 45% increase in click-through rates, an 8% boost in return on ad spend (ROAS) in Germany, and a 13% rise in Spain. This kind of round-the-clock content production eliminates the tradeoff between speed and localization.
AI platforms go beyond just translating words - they adapt idioms, humor, and even visual elements to suit local tastes. This is especially crucial in social commerce, where cultural nuances can make or break a sale. For instance, 42% of U.S. consumers will abandon a purchase if their preferred payment method isn’t available.
TwinTone as a Case Study

TwinTone is setting the bar for culturally tuned, AI-driven content. Their technology creates "AI Twins" of creators, enabling them to produce on-demand videos and host livestreams in over 40 languages - all while keeping the creator’s voice and personality intact.
TwinTone’s approach focuses on three key areas. First, it ensures the AI Twin mirrors the creator’s original tone, style, and personality, rather than just translating content. Second, it allows brands to generate content instantly, bypassing the delays of traditional coordination. Third, it provides analytics to track how localized content performs in different markets, enabling continuous improvements.
This strategy is particularly impactful given that seven of the eight top markets driving global mobile game downloads in mid-2025 were non-English speaking. TwinTone’s API access lets brands scale up by programmatically generating localized content for entire product catalogs. On top of that, their AI-powered livestreaming feature enables real-time, shoppable streams on platforms like TikTok, Amazon, YouTube, and Shopify. Each stream is carefully adapted for local audiences while preserving the creator’s authentic presence, making it easier than ever to connect with global consumers.
Conclusion: The Future of Cultural Adaptation in AI UGC
AI localization has evolved far beyond simple translation. One key advancement is addressing the "explicit-implicit localization gap." This concept highlights how language models are rich with cultural knowledge that often remains dormant unless specifically prompted. Techniques like cultural steering vectors now make it possible to adjust internal model layers (commonly layers 23–30) to automatically activate the right cultural context. This innovation helps produce diverse, authentic content while steering clear of the stereotypes that explicit prompts can sometimes generate. These advancements are already showing measurable improvements, though challenges remain.
For instance, current AI models still struggle with low-resource languages and often perform poorly without explicit cultural guidance. Interestingly, the cognitive style of these models shifts depending on the language used - Chinese prompts tend to bring out interdependent, holistic thinking, while English prompts lean toward independent, analytical reasoning. By tapping into these cultural nuances, platforms can create content that feels genuinely local rather than merely translated. Datasets like CultureVerse, which includes 19,682 cultural concepts from 188 countries, are instrumental in training models to recognize regional details like symbols, gestures, and references across both text and video.
"Cultural knowledge, while present in these models, may not naturally surface during multilingual interactions."
– Veniamin Veselovsky, Researcher, Princeton University
As discussed, understanding and applying cultural nuances is crucial for creating content that resonates. TwinTone is already putting these ideas into action, scaling AI localization strategies outlined in this article. By deploying AI Twins that retain each creator’s unique voice while adapting to over 40 languages, TwinTone showcases how cultural steering and adaptation can transform social commerce. This shift from basic translation to deeper customization allows brands to produce localized product demos and multilingual AI livestreaming that connect with audiences - from Seoul to São Paulo - without manual intervention or cultural missteps. As AI continues to bridge the localization gap, platforms that focus on cultural specificity rather than a one-size-fits-all approach will shape the future of global engagement.
FAQs
How does AI adapt to cultural differences in language and style?
AI systems draw from a wide range of global data, which allows them to grasp different cultural subtleties. However, without specific guidance, they often lean toward an "English-centric" perspective. By weaving cultural context into prompts, you can make the AI's responses feel more relevant and genuine.
To make AI outputs more aligned with local cultures, techniques like fine-tuning models with region-specific datasets or applying cultural customization vectors come into play. These approaches tweak language and style to better match cultural preferences. That said, implementing these strategies requires care - there's a fine line between adapting to cultural norms and unintentionally reinforcing stereotypes or narrowing the diversity of responses.
A successful approach to cultural adaptation involves a mix of thoughtful prompt crafting, precise fine-tuning, and consistent evaluation. This ensures outputs remain culturally sensitive and balanced.
What challenges do AI systems face when interpreting idioms and cultural norms?
AI systems often face challenges when it comes to understanding idioms and cultural norms, and there are a few clear reasons why. One major issue is that many of these models are built using data that leans heavily toward English. Because of this, they often interpret idioms or culturally specific phrases too literally, which can strip away the subtle meanings or context - especially when working with other languages.
Another hurdle is the static and often outdated cultural data these systems rely on during training. Instead of reflecting the rich and ever-changing diversity of real-world cultures, AI tends to fall back on generalized or old-fashioned representations. This can lead to outputs that feel stereotypical or fail to account for regional differences and evolving social norms.
Finally, the way AI models are evaluated often contributes to the problem. Cultural understanding is frequently treated as fixed knowledge rather than something fluid and dynamic. As a result, models are more prone to generating content that misses the mark - whether it’s mishandling idiomatic expressions or failing to grasp cultural nuances. These gaps underscore the importance of developing more flexible and inclusive methods for improving how AI systems handle cultural localization.
How can AI better adapt to cultural differences in localization?
To make AI models more attuned to different cultural contexts, they need to be trained on data that captures specific cultural elements - like idioms, humor, color meanings, and social norms. This involves using datasets tailored to particular regions and tagging them with cultural metadata. For instance, an expression like "raining cats and dogs" should be understood as a metaphor rather than a literal description.
Beyond quality data, effective localization also relies on tools like translation memories, glossaries, and input from native speakers in real time. These resources help maintain a consistent tone and vocabulary while reducing the risk of cultural missteps. Human oversight remains critical for refining outputs, ensuring cultural appropriateness, and addressing any unclear references. Platforms such as TwinTone demonstrate how these methods can help create culturally sensitive AI that delivers relatable, on-brand content for diverse audiences.




