
Cross-Modal Emotion Fusion for AI Livestreaming
How to build a futureproof relationship with AI

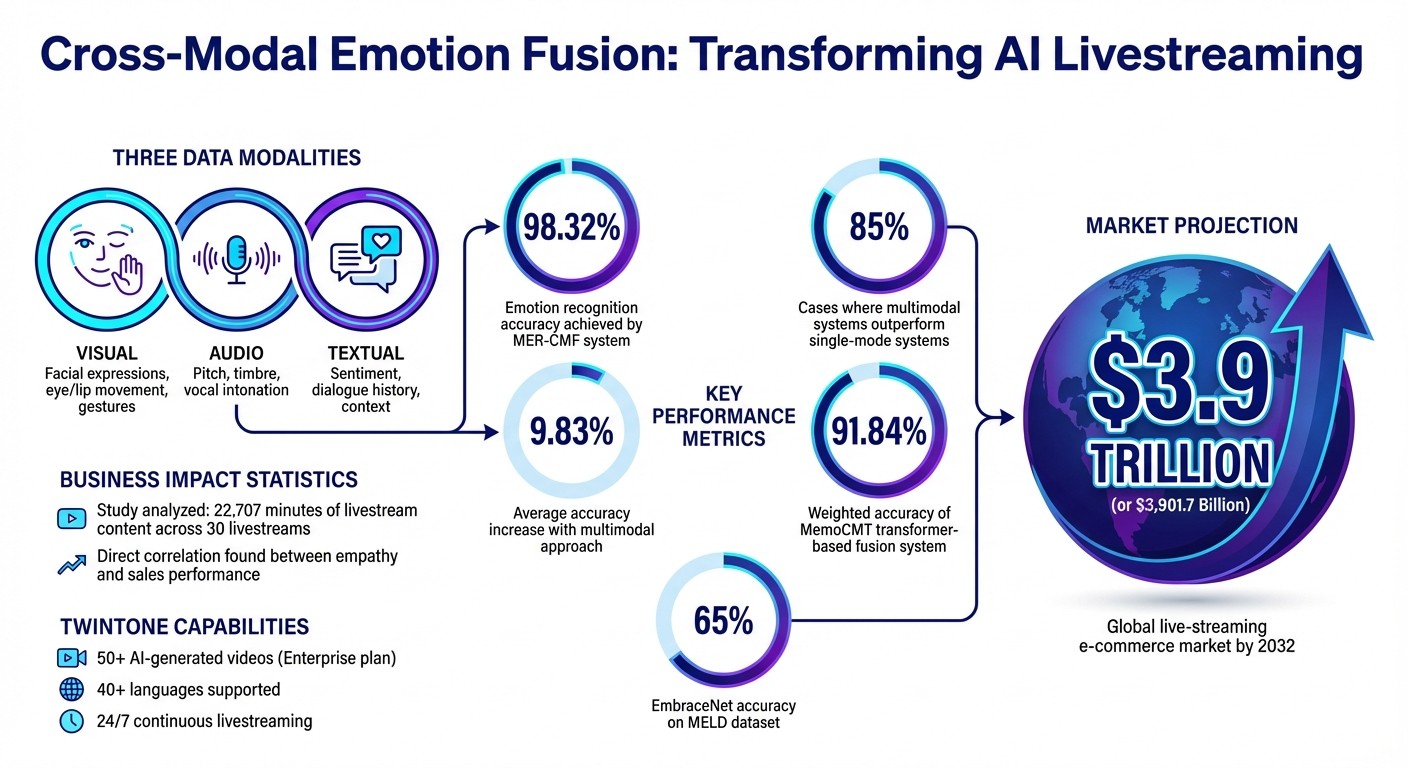
AI livestreaming is becoming smarter. By combining visual, audio, and text data, cross-modal emotion fusion enables AI to interpret emotions in real time with up to 98.32% accuracy. This technology helps AI understand subtle emotional cues, like detecting frustration behind a polite smile or sarcasm in tone.
Here’s why it matters:
Better Audience Connection: AI can now respond to emotions more naturally, creating interactions that feel less robotic.
Improved Retention & Sales: By spotting signs of disengagement or hesitation, AI can adjust its delivery to maintain viewer interest and boost conversions.
Advanced Techniques: Tools like BERT and WaveRNN process text, audio, and video data, while cross-attention mechanisms align these inputs for precise emotion detection.
Brands like TwinTone are already using this tech to power AI avatars that host livestreams, predict audience reactions, and drive social commerce on platforms like TikTok and YouTube. With the live-streaming e-commerce market projected to hit $3.9 trillion by 2032, cross-modal emotion fusion is shaping the future of online engagement.
Cross-Modal Emotion Fusion: Key Statistics and Performance Metrics for AI Livestreaming
Benefits of Cross-Modal Emotion Fusion in AI Livestreaming
Improving Emotional Connection with Audiences
Cross-modal emotion fusion allows AI to pick up on subtle emotional cues during livestreams, creating a more human-like interaction. For instance, when someone types "It's okay" in the chat, a text-only system might interpret it literally. But by analyzing facial expressions and vocal tones together, AI can detect if the phrase is actually masking frustration or disappointment. This deeper understanding transforms what could feel robotic into interactions that seem genuinely empathetic.
Imagine a scenario where visual cues from a viewer appear neutral, but their vocal tone carries irritation. The AI can recognize the negative sentiment and respond appropriately. Researchers refer to this as "empathetic response generation", where AI mirrors the emotional state of the audience through thoughtful replies. The results are impressive: multimodal systems outperform single-mode systems in 85% of cases, with an average accuracy increase of 9.83%.
Take the example of AIVA, an AI companion launched in September 2025. It detected a user’s frustration over a dropped phone by combining visual and text analysis, then responded with a sympathetic message and adjusted its avatar’s expression to match the mood.
This ability to tune into emotions not only strengthens the bond between AI and its audience but also sets the stage for better engagement and stronger connections.
Increasing Audience Retention and Conversion
AI livestreams that respond to emotions in real time have a big impact on keeping viewers engaged and driving sales. By spotting signs of disengagement - like pauses or shifts in sentiment - the system can make real-time adjustments to keep viewers interested. If someone seems bored or confused, the AI might tweak the pacing, simplify the content, or change the presentation style to recapture their attention.
For e-commerce live shopping, this technology directly boosts sales. AI can track behaviors like hesitation before checkout and respond with timely actions, such as offering a discount or recommending a similar product. By analyzing a combination of visual cues, speech, and chat reactions, the system identifies what resonates most with viewers. This data can then be used to create promotional highlights or social media clips that target potential customers.
Thanks to its high accuracy in emotion recognition, the system minimizes missed opportunities and maximizes conversions. The Partnership on AI emphasizes the broader potential of this technology:
If artificial intelligence can help individuals better understand and control their own emotional and affective states, there is enormous potential for good and a better quality of life
. For brands, this translates to livestreams that feel less like one-way broadcasts and more like genuine conversations - conversations that turn casual viewers into loyal customers.
Key Components and Techniques of Cross-Modal Emotion Fusion
Multimodal Data Extraction and Processing
Cross-modal emotion fusion combines three main data streams: visual, audio, and textual inputs. Each stream undergoes distinct processing to prepare the data for integration.
For visual data, earlier methods relied heavily on CNN-based models. Now, spatial attention blocks focus on critical facial areas - like the eyes, lips, and overall contours - while temporal models such as Gated Recurrent Units (GRU) track changes in expressions over time. Audio processing transforms raw sound into spectrograms, which are then analyzed by tools like WaveRNN and 1D CNN to capture nuances in pitch and vocal quality. Textual data is processed using transformer-based models like BERT or GPT, which create sentence embeddings incorporating the current message, dialogue context, and possible responses.
"Visual input alone cannot be relied on because one can put on a smile to conceal their feelings." – International Journal of Computational Intelligence Systems
One major challenge is aligning these diverse data types. To address this, systems often upsample video features to match the processing rate of audio data, ensuring synchronization across modalities in real time. The MER-CMF system demonstrates the effectiveness of this approach by achieving an accuracy of 98.32%, leveraging the combined strengths of audio and video inputs.
This careful extraction and alignment process lays the groundwork for advanced fusion techniques that bring these modalities together seamlessly.
Techniques for Cross-Modal Fusion
Once the data is extracted, fusion techniques integrate the modalities to provide a unified emotional understanding. One method, cross-attention mechanisms, uses Query (Q), Key (K), and Value (V) mappings to emphasize critical features in one modality based on another. For instance, when a video shows a neutral facial expression, audio cues can take precedence to improve emotion detection accuracy.
Another approach is EmbraceNet, which employs docking layers to standardize data sizes and an embracement layer to ensure the system remains functional even if one data source is incomplete. As researcher Baijun Xie explains:
"The embracement layer... acts as a regularization step, preventing the model from excessively learning from specific modalities"
Using this technique, EmbraceNet achieved a 65% accuracy rate on the challenging MELD dataset, outperforming models that rely on a single modality.
Transformer-based fusion represents another advanced method. By using multi-head attention, these systems synchronize features across modalities. For example, the MemoCMT system integrates HuBERT for audio and BERT for text, achieving a weighted accuracy of 91.84%. These techniques go beyond merely combining data - they capture the intricate relationships between spoken words, tone, and facial expressions.
Modality | Primary Extraction Tools | Key Features Processed |
|---|---|---|
Visual | Facial textures, eye/lip movement, gestures | |
Audio | WaveRNN, Spectrograms, 1D CNN | Pitch, timbre, vocal intonation |
Textual | GPT, BERT, Transformer tokens | Sentiment, dialogue history, contextual embeddings |
Applications of Cross-Modal Emotion Fusion in AI Livestreaming
TwinTone's AI Livestreaming Solution
TwinTone takes audience engagement to a new level by using cross-modal emotion fusion to power its AI Twins - digital versions of real creators that host interactive, continuous livestreams. These AI Twins analyze emotional cues from multiple channels, including facial expressions, voice tones, and viewer comments, to adapt their delivery in real time. By doing so, they create a natural, responsive interaction with the audience. For instance, if the AI detects excitement in viewer comments or an upbeat tone in reactions, it can adjust its presentation style to match the mood, making the experience feel more personal.
The platform also uses emotional and cognitive analytics to predict what will keep viewers engaged. If an AI Twin notices rising interest - like an increase in comments or viewer participation - it can shift its focus, highlighting key product features or adopting a more conversational tone. This real-time adaptability not only keeps viewers hooked but also drives higher conversion rates. TwinTone’s AI Twins are particularly effective for creating shoppable videos, where they demonstrate products live, allowing brands to host interactive shopping streams on platforms like TikTok, Amazon, YouTube, and Shopify. This level of interaction doesn’t just enhance engagement - it makes emotion-driven social commerce scalable and efficient.
Scaling AI-Powered Social Commerce
Cross-modal emotion fusion is revolutionizing how brands scale their social commerce strategies by automating the creation of emotionally resonant content. A study analyzing 30 livestreams, covering 22,707 minutes, found a direct link between streamer-viewer empathy and increased sales. TwinTone builds on this insight by training its AI Twins to establish "empathy transmission chains." These chains synchronize the AI's emotional tone with the audience's mood, fostering genuine connections that encourage purchasing decisions.
This approach is especially impactful for products like beauty or lifestyle items, where value is often perceived through subjective experiences. Emotional resonance plays a key role here, helping viewers feel more connected to the product through live demonstrations and relatable descriptions. With TwinTone’s Enterprise plan, brands can scale this process effortlessly - deploying over 50 AI-generated videos across various product lines. Each AI Twin preserves the original creator's style, personality, and tone, while also delivering content in 40+ languages. This eliminates the delays and costs tied to traditional influencer collaborations, ensuring that brands maintain emotional authenticity while reaching global audiences. Considering the global live-streaming e-commerce market is projected to hit $3,901.7 billion by 2032, this technology positions brands to thrive in an increasingly competitive landscape.
He Built an AI Model That Can Decode Your Emotions - Ep 19. with Alan Cowen
Conclusion
Cross-modal emotion fusion is reshaping how AI enhances livestreaming experiences. By analyzing a combination of facial expressions, vocal tones, and text, these systems achieve a level of emotion recognition that far outperforms single-channel methods. This multi-layered approach helps capture the subtle emotional cues that are key to forming genuine human connections. And it’s not just about technical precision - it’s about fostering emotional resonance that can directly impact sales and audience engagement.
The business implications are clear. A study examining 22,707 minutes of livestream content revealed that empathy between streamers and viewers consistently led to stronger sales performance. This happens because viewers naturally mirror the emotions they observe. AI tools like TwinTone’s AI Twins replicate this dynamic, maintaining meaningful emotional connections across platforms, languages, and time zones - 24/7.
As these insights drive innovation, the AI livestreaming landscape is advancing rapidly. With the global live streaming e-commerce market expected to hit around $3.9 trillion by 2032, brands that embrace cross-modal emotion fusion will gain a clear advantage over their competitors.
For companies aiming to lead the way, the solution is simple: invest in AI systems that can interpret and respond to emotions across multiple channels. TwinTone's approach - blending real creators' authenticity with AI-driven emotional intelligence - is a powerful example of how technology can amplify the human touch that influences purchasing decisions. The future of social commerce belongs to platforms that offer consistently personal and emotionally responsive interactions.
FAQs
How does cross-modal emotion fusion enhance AI-powered livestreaming?
Cross-modal emotion fusion brings together visual signals (like facial expressions), audio cues (such as tone and pitch), and textual inputs (like chat messages) to form a cohesive understanding of emotions. By blending these different channels, AI can interpret emotions with greater precision, even when one source is unclear or noisy.
In the context of livestreaming, this technology enables AI hosts to sense audience emotions in real time. For example, it can pick up on excitement from smiles, enthusiasm in voice tones, or positivity in chat interactions. The AI then adjusts its expressions, tone, and timing to align with the audience's mood, creating a more natural and engaging interaction. This responsive approach strengthens emotional connections, boosts viewer engagement, and leads to better outcomes, such as longer viewing sessions or increased purchase intent.
TwinTone leverages this advanced emotion fusion to empower its AI Twins during livestreams. These AI hosts continuously interpret audience feedback, delivering emotionally attuned, seamless experiences that keep viewers hooked and drive results - all without delays or the need for manual intervention.
How does cross-modal emotion fusion enhance AI-powered livestreaming?
Cross-modal emotion fusion brings together data from various sources - like audio, video, and text - to create a more cohesive understanding of emotions. This approach allows AI systems to interact in ways that feel more natural and responsive. It relies on advanced techniques like multimodal feature extraction, which picks up on crucial cues such as facial expressions, tone of voice, and text sentiment. Additionally, attention-driven deep learning ensures these different signals are combined smoothly and effectively.
Using transformer-based architectures and adaptive fusion methods, platforms such as TwinTone can analyze these inputs in real time. This enables AI-powered livestreams to detect and respond to audience emotions as they happen, fostering deeper engagement and emotional connections. The result? A new way for brands to create meaningful interactions with their audiences.
How can brands use cross-modal emotion fusion to drive more e-commerce sales through livestreaming?
Cross-modal emotion fusion brings together visual, audio, and textual cues during a livestream to better understand the emotions of both the presenter and the audience. By analyzing facial expressions, tone of voice, gestures, and language, this technology creates a stronger emotional connection, which can help build trust and even drive purchases.
Brands can tap into this technology for AI-powered livestreams through platforms like TwinTone. With TwinTone, brands can develop AI versions of real creators who can adapt product demos, visuals, and offers in real time based on audience reactions. For instance, if audience excitement spikes, the livestream might spotlight a product or introduce a limited-time discount. This kind of dynamic interaction not only strengthens emotional engagement but also boosts key metrics like click-through rates, engagement, and sales revenue, making live shopping experiences far more impactful.




